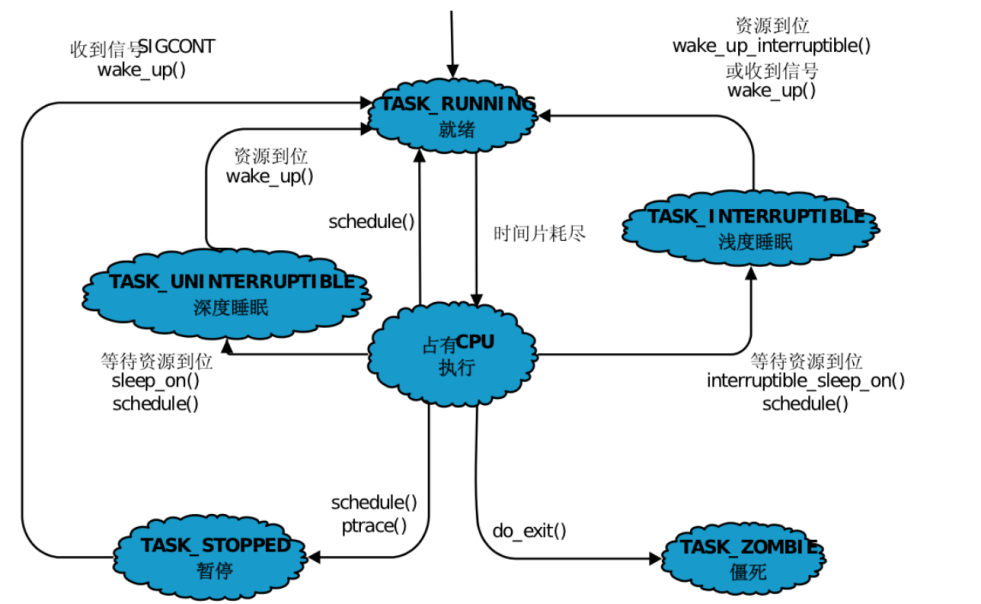
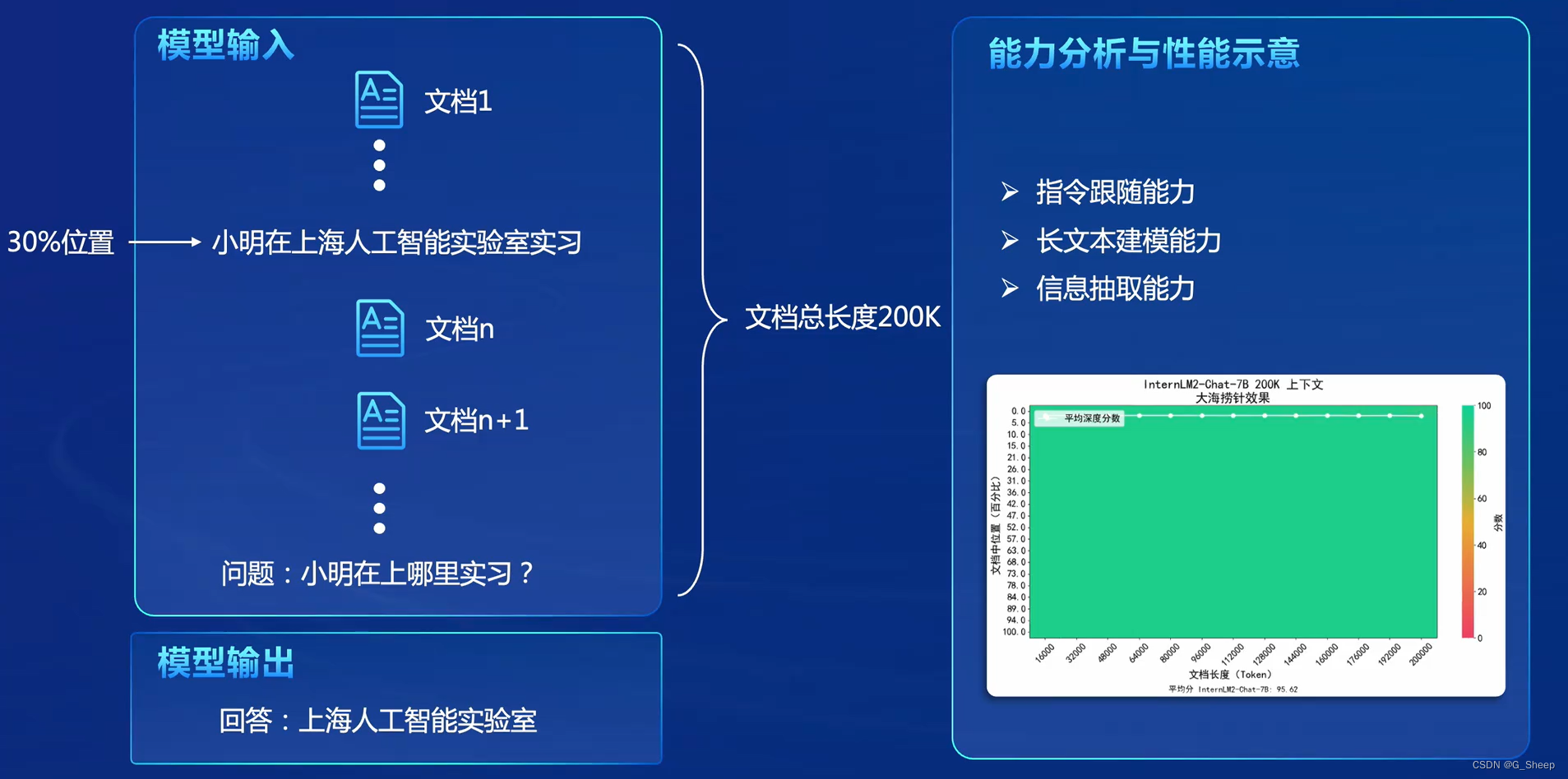
决策智能不应该停留在以前的思维中了,现在开一个专题来学习一下决策论坛的老师们的精彩的内容。本内容来自决策大模型论坛,张伟楠老师的内容整理。
决策大模型
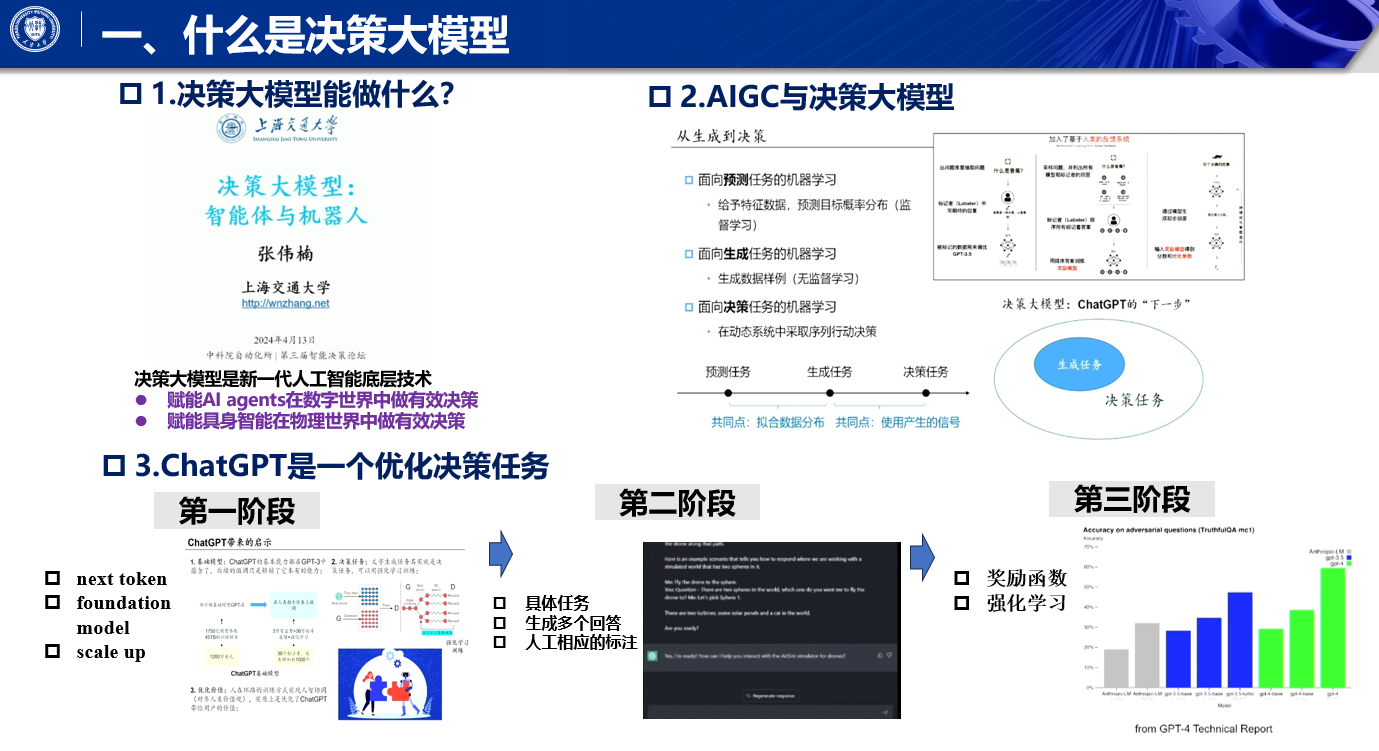
是新一代人工智能的底层技术,它可以去赋能,智能体也就是AI agent,在数字世界当中去做出有效的决策,它也可以去赋能具身机器人,在物理世界当中做出有效的决策。
首先呢,我们主要是探讨这个,从生成到决策的一个范式的一个转变,因为我们其实这个论坛名字,叫做决策大模型,大家肯定会问说,那它和AIGC啊,在做生成式的大模型之间啊,决策大模型到底有什么样的区别呢,其实我们从机器学习入手,我们可以看得出来啊,机器学习当中其实有三类的问题啊,首先是预测问题,面向标签预测的这种有监督学习,去构建一个损失函数,然后最小化它来解决它,比如说分类、回归等等。那么第二个任务呢,叫做生成任务啊,往往是构建出一个拟合数据的这个最大化log(likelihood)这种方式,然后学到了分布之后呢,再从分布当中去采样它,背后的一个基本的一个技术呢,就是机器学习当中的无监督学习的技术,而第三部分内容呢,其实在我们人工智能当中,对于决策任务而言的话呢,在机器学习当中,也是有强化学习这样的一些工作,
预测型任务和生成式任务,还有决策式任务,生成式任务和预测型任务相似的点就在于,他们共同的拥有一个拟合数据分布的这样一个训练的过程啊,而生成式任务,它和决策式任务比较相似的一点则是,他们共同的,可以去使用模型产生出的数据,产生出的一些信号,
ChatGPT在训练的过程的这个三个阶段,则正好印证于这三个阶段,第一个阶段呢,是说我通过next TOKEN,prediction的有监督学习的损失,来去拟合出一个foundation model,这个过程呢,我们必须要将我们的学习任务,以及学习的架构本身做的非常的啊,可以scalable啊,scale up。第二个点呢,则是说我让我们的这个模型啊,比如这个GPT模型去对于一个任务呢,产生我们生成啊多个回答啊,基于这个多个回答呢,当然,我们会去做一些人工相应的标注啊,原因就是因为我们得做第三类任务啊,决策优化的任务,但是有一个关键点就在于,第二类,第二个阶段的这个标注的数据,得一定是基于啊,模型本身生成的数据啊,那么第三个阶段呢,则是通过学习好了奖励函数之后呢,在我们的这个基于奖励的这个指引下,去做强化学习啊,这样最终呢,我们chatgpt是一个实打实的一个优化决策的任务。
智能决策这样一个领域当中去啊,我们来啊,看看过去啊,的它的一个基基本的技术发展,在2012年以前的话,智能决策主要,使用到的一些技术,统称是类似于像是专家系统这样的一些技术,原因是要让一个决策智能真的可以工作的话,我们往往会需要有一个researcher啊,Developer,它首先在这个决策智能的任务上,他自己就是专家啊,基于这个任务的话呢,我们将这个专家的支持啊,扣银扣的在我们的模型当中啊,无论是我们的啊,搜索当中的一些价值函数,还是我们直接将这个任务,变成是一个优化问题啊,再用solver去求解它等等啊,这都是我们human得,首先成为理解这个任务的一个expert,那么基于这个export的system啊,我们可以去构建出一个,决策的一个解决方案,
那这样的一个逻辑的话,就会导致说,我们要铺啊决策智能的广泛应用,我们就得需要很多的human efforts啊,甚至是expert efforts,在这种情况下,其实是一个比较大的一个瓶颈对吧,那么这个瓶颈是如何解决的呢,在2012年的时候,2013年开始啊,deep mind提出了深度强化学习,在这个时候,智能体不需要,不需要human的一个一个expert dominology,而是说直接和环境进行交互,通过交互处的experience data,使用深度强化学习,我们就直接能够,较为自动的,去提升智能体的performance啊,
这个方法固然好,我们也是在很多游戏啊啊,这个发现一些物理结构啊啊啊,这方面去取,得了不错的效果啊,但是大家会发现,深度强化学习他在做跨任务,跨场景泛化的决策任务上,其实会碰到相当大的麻烦,原因是因为深度强化学习,他本质上是在,你和到一个动态环境当中的一个啊,我们也可以叫它漏洞,也可以叫它,就是说我可以去充分的去,exploit这个环境啊,它exploit的方法,就主要是使用的是贝尔曼最优迭代式,啊贝欧贝尔曼最优迭代式,将第二步的最大最大价值啊,引传到第一步上去,这样做的话,如果我的环境去,发生了相应的改变的话,那么这个传递,其实是将相应的一些拟合的error,往前去传,这样子,使得我们深度强化学习不太容易啊,我们说不太容易能够跨任务啊,或者跨环境去拟合啊,去做好做好泛化啊,
那么从22年开始呢,我们啊也是和世界其他团队提出说,我们有没有可能在决策这个方向上啊,提出类似于面向决策任务的大模型,因为在那个时候,自然语言处理已经在多个任务上,多个场景下啊,他都能够去使用一套模型,去做出有效的泛化,那么我们有理由相信说这一套,比如说基于Transformer这一类的模型,是有可能在多个决策任务上,去做出有效算法的,所以说在那个时候,我们开始推啊这个面向决策大模型。
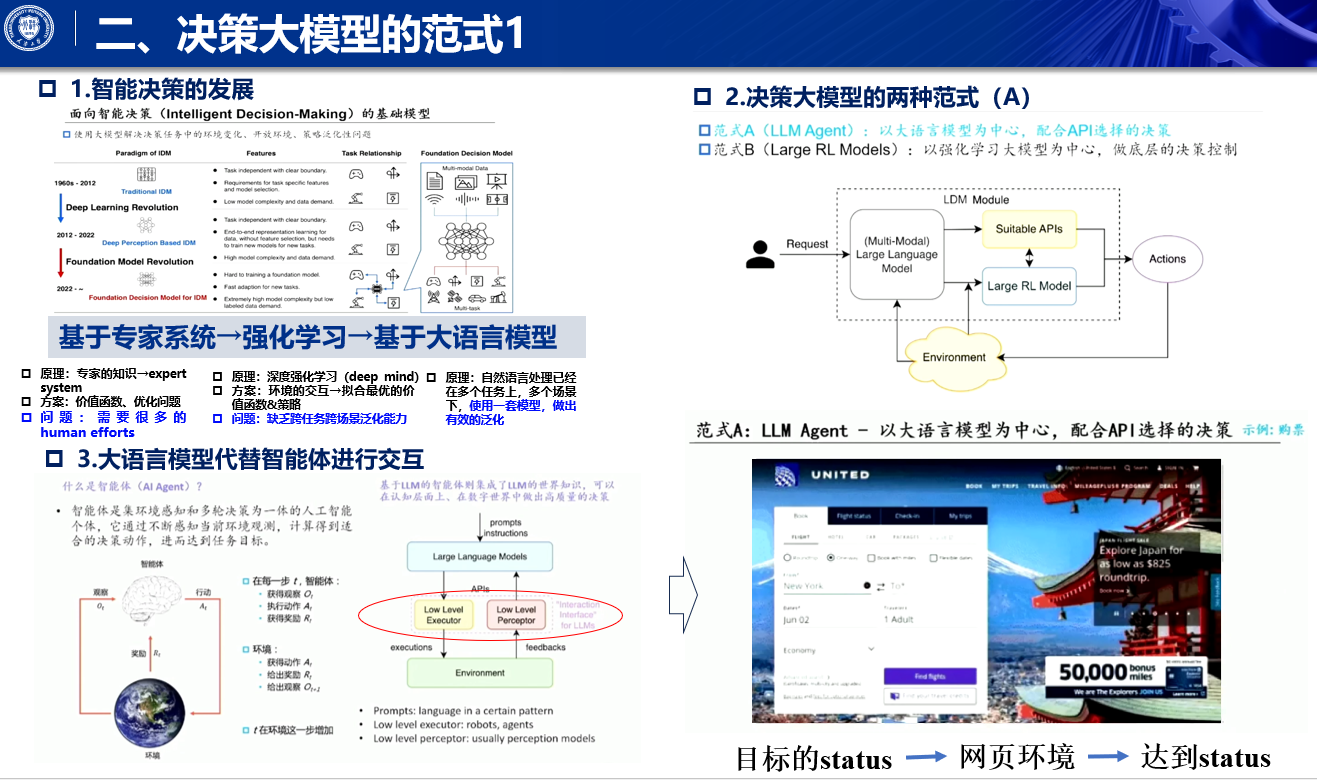
两种范式
而到目前为止,决策模型其实已经发展成为了两种范式,范式a的话,是基于大语言模型为中心,构建出的agent,它可以去通过API的方式,调用相应的工具,去和这个user也好,去和system也好,去做出一个较为standardized的一个交互,我们叫它LLM agent,
我们首先来看一下范世a啊,张老师介绍了一些比较初级,入门级的一些一些观点啊,什么是智能体本身呢,智能体其实它是一个被,它是一个承载着啊,人工智能技术的一个实体,它可以不断的,和环境进行多轮的交互,交互是什么呢,得到环境当前的观测通过,计算呢得到具体的决策动作,进而将这个动作下达到环境当中去,得到环境的反馈,并且开始下一轮的感知决策啊,这样的交互,
这样的一种情况下,我们将大语言模型,去代替掉中间的这样一个智能体啊,去做环境的感知,去做出决策的选择的这么一个模块,当然,大语言模型智能体本身它是语言模型,它得它的输入输出,它都得是语言的token,所以说,我们往往会配上这个low level的啊,perceptor和executor,使它能够和各种各样的环境,进行交互啊,
像是大模型,它可以和我们的网网页环境进行交互,它作为一个智能体,作为个人助手,它可以去帮助我们user,去提供一些像定机票啊,去订酒店啊这样的一些服务啊,最终呢我们其实是用户心中,他其实想着是一个,我要achieve到的一个目标的状态啊,然后大圆模型通过和通过工具调用,或者通过和环境进行交互,最终啊,带这个用户走到他要的那个目标状态,我们其实user,它如果希望,能够检索到一些相应的文档的话,其实它的目标其实是达到某个status,然后通过agent的方式操作,最终我们可以走到这个status,而这个目标的status,我们完全可以是有一些别的,非信息检索的一些任务,比如说哎,我希望我家里面的冰箱里面,今天晚上出现青椒啊,那我其实是可以让我的agent,在网上去下单,去购买相应的青椒,并且送到我家里面啊,这是一种新型的一种啊,去达到某一种新的状态的,一个一种范式啊
包括我们梁一涛老师之前提到的,这个depths工作,可以让LM major和像Minecraft这样的游戏,去做相应的交互,去玩出来一些新的高度的performance啊,包括这个啊,Meta GPT啊之类的啊,通过把SOP注入到我们的啊,多正体协作的工作流当中,使得在这个协作过程当中,不要过于的发散,最终能够去协作出一个软件project,
像to former这样的任务,其实我觉得是一个啊最非常基础,但是能够产生啊,较为深远影响的工作啊,通过让agent通过大圆模型啊,它能够去呃,选择调用一些工具的API啊,然后将工具的API返回的结果呢,填充到它即将去啊,填补的这些文档的空缺的位置,最终完成一个更好的question answering啊,但其实啊,不止是question answering,它其实也是完全可以进一步的,将吐出来的这样一些文字啊,这些信号,再次去应用到下一步的这个决策,迭代当中去,去解决更加复杂的相应的问题啊,
所以说呢,我们其实LMH呢,他自己本身,还是可以去产生一些思维的,推理的因为我们做action的时候呢,大家可以发现,我们定义action本身,其实定义的是,它和环境可以直接进行交互的,改变,这个环境的信号我们叫action对吧,那如果说我产生一些信号,他不deliver到环境当中去,就在就像我们脑子当中产生过去的话,那么我往往叫思维吧,叫thought对吧,这thought,其实能够有助于我们进一步的,去做更加复杂的任务的推理,但是它不直接deliver到环境当中去,产生相应的影响,所以说在这将这两者结合的话,其实就会有类似于像react这样的工作,reasoning和action,都在同样一个framework下去做,输出但是呢,只有action会最终deliver到反应当中去,而reasoning中的thought,会帮助大语言模型进一步的去产生额外的一些思考啊,那么包括chain of thought,tree of thought都可以被更多的利用,
既然他有这样一个tree of thought的结构,当然可以像阿尔法go当中的MCTS,这样的一些技术,学习额外的一个价值函数啊,使得我们能够大致的知道说,往哪边去搜索啊,哪些action,最终deliver的一个后果是好的,哪些的后果是坏的,然后,在这样一个比较庞大的决策树下,可以去引导我们大语言模型,去做出相关的减枝,最终通过look ahead的技术,能够产生出啊当前可以有的更好的一个action。
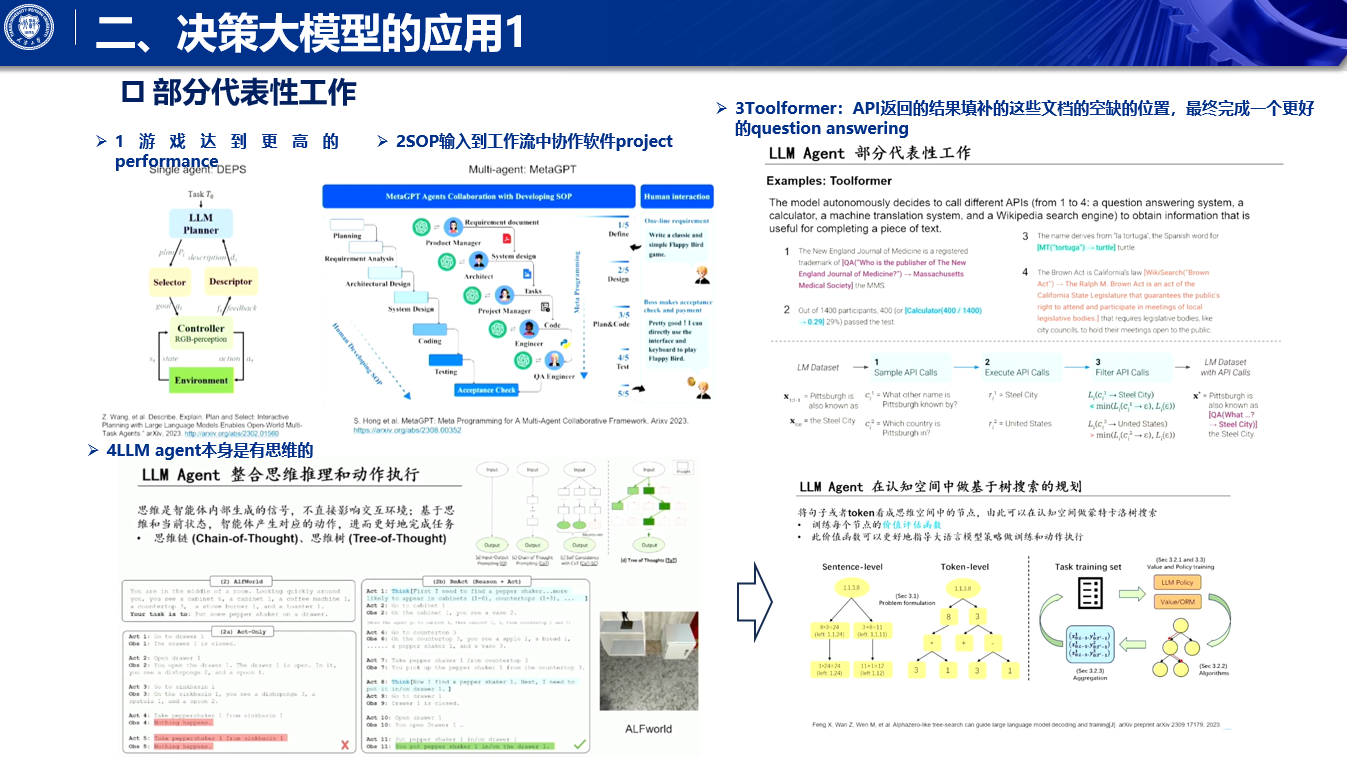

第二类的范式呢,首先第一点就是说,基本上它是一个end to end 的 training,它不只是以一个已经被训练好的大语言模型为基础,更多的是,它就是一个强化学习的框架啊,然后呢,我们将强化学习当中的一些Module啊,去做出一个模型的一个更改,去完成跨任务跨环境的这样一个泛化,

这个范式下的话,我们往往训练的过程,就和一般的强化学习还会有所区别的,原因是因为我们既然是希望我们的,比如说一个agent,它能够在不同的任务上去做出泛化,那么往往我们训练它的一个范式,就变成了是goal condition reinforcement learning,而不是说我们是使用单一的奖励函数,它其实奖励函数源自于goal,goal怎么设计,奖励函数将会相应的被发展出来啊,
强化学习本身,它是由这么一些module构成的,像策略价值啊,等等,为什么他可以被这些model,为什么可以被大模型化啊,这行公式呢,其实是我自己呃总结出来一行公式啊,大家可以看到这公式当中呢,其实是有有这么几个模块出现,第一个模块呢,其实是我我我优化这个模型的参数啊,这第一个模块呢,其实是从某个数据分布下,我采样得到像SA这样的payer,第二个模块呢,其实是有一个类似于加码,或者是说,有一个类似于像加这个wait的,这么一个Mac的一个操作,第三个模块,其实就是啊,我去Maximus log,likely的的这么一个操作啊,大家可以看到,如果说我这个分布,是来自于专家的轨迹数据啊,那么MSA呢,有完全取义的话,那么它就是一个behavior colonial的啊,这个imitation learning的一个工作啊,如果说这个当前的这个轨轨迹数据,来自于我们当前agent交互出来的数据,并且Mac它是一个advantage function,或者是一个value function的话,那么这个gradient,它就是一个正常的policy gradient啊,它可以用类似于对,等价为PPU等等,这样相应的工作,如果这个数据本身,是一个离线的data say,采样出来的,并且我在这个过程当中再加上一些啊,conservative的regulation的话,那么它就是一个离线,强化学习的一个framework啊,所以说我们可以看到,是可以将这样的一个framework,其实啊既然它是可以以这种啊,MAXIMUM logolike可以获得的形式啊,的一个变种去做礼盒的话,我们就可以使用,类似于像sequation modeling当中的啊,MAXIMUM logolike获得的这种训练范式,只不过我们将其中的module,改成是强化学习当中的啊,基于Transformer的module啊,那这样的一些工作的话,其实也就是啊,这个我们将不同的task下的,一些专家轨迹啊,采样出来,有的时候,我们agent选择出来的一些轨迹呢,它其实是不是特别优秀的,我可能会把它毙掉,有的轨迹呢,它特别的result特别优秀,我们将啊采样下来,把它称作成专家轨迹啊,将这样的轨迹结合在一起呢,在同样的范式之下,就是上一页的那个公式,我们可以去训练一个智能体的policy,但是这种policy,我们往往统称它为通才智能体policy,它可以去完成很多的任务啊,它可以在新的task上,可能做出feel short的泛化,但是我们也不可能是说,让它这一个policy啊,能够在每一个任务上,能够去做的非常的精通啊,这个主要原因就在于是说,这个训练范式之下,如果我们只是使用behavior clone的范式它是没有价值函数的,在这种情况下,他可能只能学习的到一个比较啊,中庸偏上的一个智能体的一个模式啊,
那么这样的工作的话,其实在21年,由Berkeley提出来的decision Transformer当中,就已经啊初见端倪啊,我们其实是将这个一个upside down,Reinforce learning啊,的一个架构,用Transformer啊去给它实现了一下,将一个目标啊,其实这个return to go啊,是在它这边的一个啊,go的一个实现,它其实是一个go啊,就是说我希望接下来,能够达到怎样的一个目标,只不过呢啊,在decent Transformer当中,它使用的是我,我们agent在这个track,接下来,它可以去取得怎样的一个return啊,作为一个具体的目标,那么当场历史上给出来的那个action,则会变成监督信号啊,因为我有go,conditionary for some learning这样一个架构,所以说我们可以通过hintsight的方式,因为我目标要达到那个go,所以说当时的action,可以反而变成监督的action啊,来去直接训练我们中间的这样一个啊,策略的一个架构啊,那当这当然策略架构如果是像sober,它可以scale up的话,我们就可以往策略大模型,这个方向去走啊啊,于是一年以后,这个ghetto啊demon ghetto被提出来,这个其实也是我在22年的决策论坛上,啊已经给大家啊,讨论过的这样一个架构啊,被提出来,它使用了一套这个统一的架构啊,去在600多个任务上啊,将所有的多模态的数据,做出了tokenization,变成sequence of tokens,然后呢通过统一的,这样一个masking的一个源头啊,比如说机器啊,比如说机器人的话,它会有不同的频率啊,那么,我们就在不同的这个频率之下呢,出action的那些位置,我们要把它标标标出来,masking变成一,要去拿那个损失函数啊,要去拿那个action loss啊,比如说在对话上面的话,question这个部分是没有损失的啊,我就不拿全部mask为0对吧,在answer这个部分,全部mask变成一啊,去拿那个answer的损失还是等等啊,包括这个玩游戏啊等等也都是一样的,但是在同样的架构之下,我们就可以去训练这个GPD only啊,decoder only的这样一个transformer架构啊,那我们团队呢,也是在这个22年的下半年的时候啊,去开展了一个,对于get的一个副线工作啊,我们其实没有没有想到,会会花那么大的efforts啊,其实呃我们整个团队,大概有投入了15个学生左右啊,在800多个任务上,首先使用深度强化学习,拟合到这个任务当中的专家策略,然后再使用专家策略,去采样这个任务当中的专家轨迹,然后再选择了相应的一些数据,最终,积累了100T的这样一个专家轨迹数据,最终呢,训练出了这样一个可以同13.2亿参数,可以去同时啊,去去完成870个任务的这样一个模型啊,这个模型在这个过程当中,其实对我们而言,更多的是一个engineering的一,个积累而并不是在这个啊,这个model design方面,有任何的一个创新啊,那么最终呢,我们的这样一个模型,它是可以在类似啊question answering啊,visual language模啊QA,然后在游戏啊,在机械臂控制,在这个一些类目九口的控制环境当中,能够超过啊,达到专家策略的性能的76%啊,也还是可以的,并且在这过程当中,还有TSP这一类的啊,组合优化的文体,将这样一类的方法呢,我们其实可以用在机器,机器人的控制上面啊,呃这是我们在IC呃,ICRA2023上的一个工作啊,我们是将机器狗啊,落落上了这样一个啊,跟地形有关的Transformer模型啊,使得它能够更好地在地形上,去完成一个泛化性的学习啊,当然这个我们被称之为啊cm two real啊,dormitorization的技术啊,它就可以比较好的啊,相比于其他架构,比较好的遵循一个目标速度矢量啊,这个速度矢量,我们现在做出来的结果是,它可以全方位的去指啊,比如说我可以除了指向啊,往左往右往前往后以外,我还可以去指向,往往往往斜上方或者是斜下方啊,使得这个机器狗在走的过程当中,他还可以完成抬头或者低头的任务,一方面去看脚下的楼梯,另外一方面去抬头看到,我们现在需要让他找到门牌号啊,这样的话,他可以有更好的一个啊,上层任务的一个解决,此外呢,我们经常会控制这个机器口呢,会出现出一些关节损坏,或者关节失灵的这样一种情况,那么以前呢,这种情况出现之后呢,这狗就直接就当场就中断了对吧,那我们现在呢,会使用类似于像啊embodiment啊,wear Transformer这种架构,或者说对它去做一定程度的,一个关节失灵的一个泛化,使得我们将embodiment本身啊,Encode进当前的像,就像就像是一个condition一样的,一个架构当中去,使得他在关节失灵的情况下,仍然能够去哎,将另外三条腿啊去使用进来,能够完成一个,即使在关节失灵的情况下,我们仍然能够去完成行走的任务的,这样一个目标,除了这个,在策略上,我们去apply比较大的规模的,这种模型以外呢,我们还可以啊,在这个价值层面上去想办法scale up,其实到目前为止呢,使用在价值函数上,去使用较大规模的这种啊,工作其实还比较少啊,但是我们刚开最开始那个MCTS那一页,给大家诠释了,是说,是可以去使用一个语言模型的架构,去就跟GPT一样,它有个头出来是evaluate当前的价值啊,但是,在n to n的training的这样一个framework下,我们仍然是去思考说,如何去使用一些,可以scale up的一些framework啊,去做更好的价值函数的一个学习啊,Google这边提出来说使用,提了一个词叫queue Transformer啊,我后来才发现,Queue Transformer,其实是大家儿时看到一个动画片的,一个变形金刚的名字啊,呃他其实怎么做呢,我们想办法将多维的action,逐位逐维的action去做成序列,化啊那么这样的话,我们就可以上一个consumer,这样一个价格,在做q learning的这样一个,我们的一方面是offline的,另外一方面是q learning的啊,那么做q learning这部分当中呢,我们可以看到,如果说是action是中间的维度的话,我们就直接把它下一个维度,我们要的Max q拿过来,这是中间维度的action的TD啊和目标,如果这个维度,已经是这一个action的最后一个维度了,那么我们就直接把reward加上,下一个time step,action的第一个维度的q啊,做TD作为TD目标拿过来啊,这样做的话,其实我就将我的action,其实拆成了一个序列的过程,这个序列过程,我们套上Transformer架构啊,他有望能够更加scalable,能够他大概是看了一下有 3,500万参数,这个参数量,虽然比一般的语言模型要少很多,但其实作为价值函数而言的话,是一个非常不错的一个大的参数模型,啊然后呢,我们就因为它是离线强化学习嘛,所以说对于当时没选择出来的action,咱往往是使用,类似于像CQL那样的一个学习架构,将它的没有选择出来的action TOKEN啊,去对于当前这样一个q,往0进行学习啊,这样的话让它变得较为保守,不要走到OD啊,数据外的这个选择过程当中去啊,就是q Transformer,它的application仍然会落在,一方面是一些游戏,另外一方面是在这种机械臂的,这个操作的过,程当中去啊,然后对于环境本身,大家已经将上午也提到了这个,孙老师也提到了这个啊,世界模型啊,我们在强化学习范畴之下呢,经常会说的是环境模型啊,就是environment Dynamics model啊,丁曼的原班团队呢,其实在1年以后啊,在丁曼的这个gather出来之后,的一年以后,又提出了一篇工作,是使用啊,几乎一样的架构,但是它build的是一个environment model,它叫称之为叫Transformer Dynamics model啊,TDM这个model呢,大概是3.6亿参数啊,这个model拟合了一些比如像类目,周口这样的一些环境,之后呢它在这个环境上,去做MPC的一个action的一个选择啊,你会发现什么呢,你会发现说相比于behavior colony,一年前的ghetto这类的技术,我们一起拟合的是一个中庸的,较为偏上的generalist agent,咱不如去拟合一个generalist environment,在这个environment的一个基础之上,咱可以去做planning,这样选择出来的action,其实它会被证明说是比啊,我选择一个中庸的,你和的generalist agent policy选择出来的action,要效果会更好一些啊,此而言儿,这个方向的话呢,这个demon又发布了,这个接领啊,就是最近发布的一个工作,它使用了是视觉生成的一个信号啊,我们可以产生数秒的这样一种,像短视频的这样一个信号,基于当前的帧数,我们可以去简单的去infer说,在一个action sequence之后啊,我们这个environment去发生何种的变化,那么将这样一个叫做呃ST Transformer啊,可以和一个lightened action model,去构建出一个更好的啊,动态模型,并且能够产生啊,我可以去play这个game啊,或者说我们去可以去根据task instruction,去想象说机械臂接下来take action之后,接下来可以走到怎样的一个状态啊,然后再去对于当前的action,去做出一个啊,修复和执行这样一个工作啊,面向于这个Marty呃Marty agent方面的话,其实我们和这个呃徐索团队啊,在22年21年的时候,其实就有一个早期的工作,当然最近啊,在去年的时候被这个MIR所接受啊,这个MR正好也是我们今天看到MIR的,这个摊位啊,我们将agent之间啊,去做了一个持续上的延展啊,并且在每一帧上呢,去完成agent之间的interaction啊,这个是沿着持续展开的,March agent decision Transformer的工作,它能够被证明是说,可以在大量的离线数据之上啊,能够去训练得到一个基础的啊,March agent control the policy和act,然后呢我们可以在一些在线的,这个新的一些任务上,去做出额外的微调啊,包括actor,包括啊我们的critic啊,最终呢,能够在类似于像心计这样的任务上,能够取得更好的新环境上的,一个feel show的泛化的能力啊,此外呢我们后续也会发现,说a证与a证交互,可以将a证看成是一条序列啊,比如说有10个a证的交互,可以看成一条10个a证的,组成序列,大家可能会说,我为什么要将a证看成序列呢,啊其实也是序列,也可以不是序列,因为全松文本身它虽然叫序列模型,对吧但是它,其实它是不是一个在序列上去做啊,这个循环层的这样一个模型,所以说它只是将position encoding啊,放到了,我们的这个set的每一个elements当中去,啊所以说我们是有理由相信,将将agent本身去做出一个啊,序列化的这样一个建模,之后呢我们在允许中心化执行的,这样一个setting之下,是可以让我们所有的item的,是在每一帧,首先去计算出相互coordinate的action,然后在一起deliver到environment当中去,这样做的话,它的它的这个coordination的啊,这个架构,就会比centralized的,training d,centralized execution的这种架构会更强啊,只要我们的环境,我们的setting啊,是允许我们做中心化执行的,那么我们何不使用中心化执行的,这样一种架构呢,啊,所以说,无论是星际还是呃Google research book,呃呃Google这个footbook啊,他都可以,只要我们的呃,这个执行器满足这个相关的要求,他就可以去做出中性化的执行,那么中性化执行的话,大家就可以同时去采样,选择出相关的动作,在一起deliver到environment当中去,这样做的好处在于说,有的agent,它就可以去condition on前续,agent已经可以准备产生的action,然后再去计算,当前我这个agent应该可以产生的action,而这个过程,我们可以使用啊Transformer的架构,去对它进行一个啊sequence建模,无论是啊Critic的建模,还是每一个agent policy建模,它都可以去使用这个架构,我们称它为Marte agent transfer这个架构,这个架构在后续的一些呃,这个Benchmark当中,也是可以被,被证明说是一个SOTA级别的performance,当然这个对比的别的performance的话,也也很也很正常,原因是因为,别的算法大部分都是centralized training的,centralized execution啊,而我们这个mat呢,它其实是centralized execution的,所以说本身呢,setting也确实是要更加容易获得,coordination的能力的啊,

总结
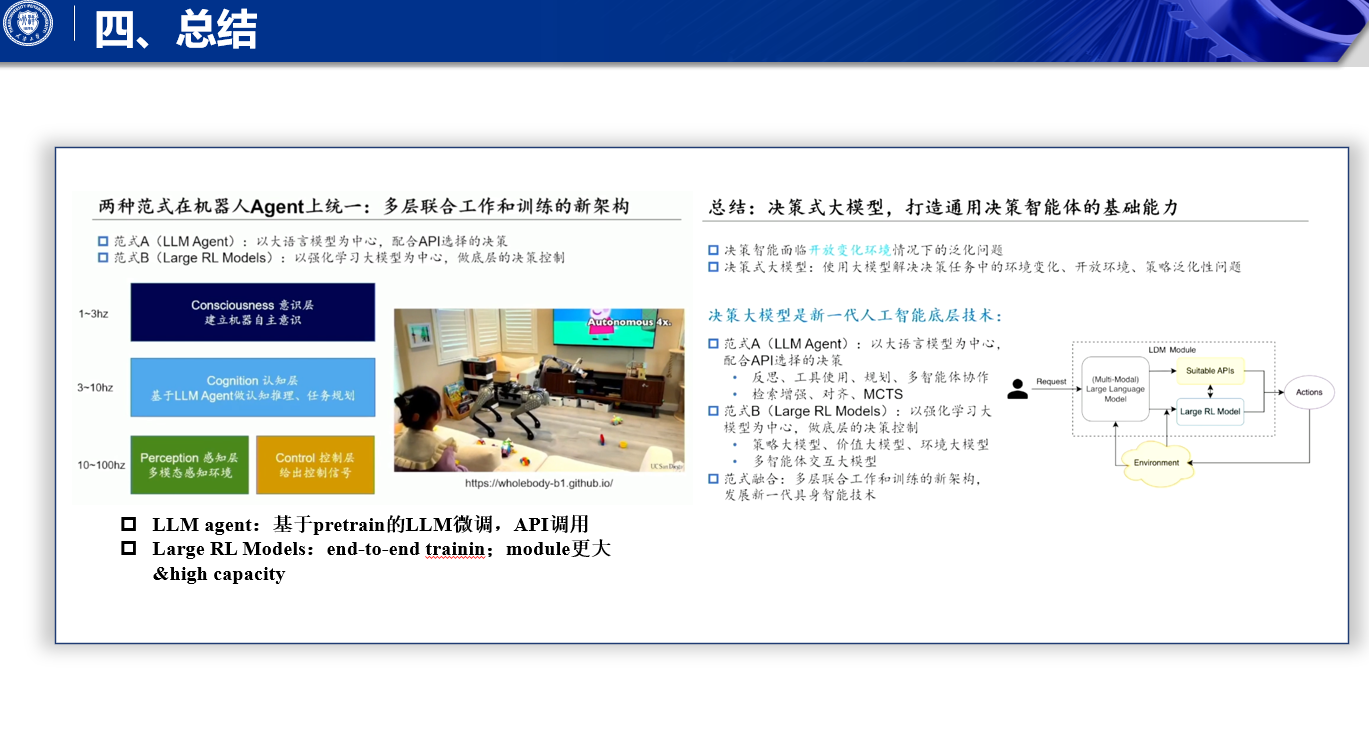
好那么这两种算式,我们刚刚其实讲了一种是LM agent,它其实是基于一个pretrain好的大语言模型,去作为基础啊,然后在一些任务上去做啊,对其法人丘陵等等啊,还有另外一种任务呢,则更多的是一个端到端强化学习,只不过我们是将它的module去做的更大,更有更high capacity,这两种范式,其实,我们可以如何对它进行一个融合的,啊,其实在目前大家可能会越来越关注的,聚身智能,这个方向上,可能会得到一个融合啊,除了我我我这边提到的一个点,其实是不只是双层啊,可能是有三层架构,
当然最高的这层架构叫consciousness层呢,其实还没有太多的工作在这上面,它可能是一个1到3赫兹左右的,这样一个频率,在控制这个机器人的自主意识啊,基于此呢,我们下面会有一个3到,10赫兹左右的这个这个认知层啊,是基于我们当前的啊,vision language model或者是纯language model agent,去对于当前的任务啊,去对于当前状态去做评估,去做出认知,做出任务的规划啊,然后呢我们下底层其实会有这个啊,对于环境的感知层,和我们底层的动作的控制层啊,包括我们之前去控制机器狗,或者说控制人形机器人,它都是有一个五十赫兹以上的,这样一个啊,控制的一个频率啊,再和环境进行交互,但是这个频率,它很显然,是不可能有当前的大语言模型啊,或者是大的微信language摩托去控制的,而更多的是一些比较小的控制模型啊,它可以更好的,去和中层的这样一个认知模型,进行交互,共同完成啊,这样一个控制,此外这个这个分层架构呢,它其实不不像我们之前讲的,to use那种架构啊,to use那种架构,其实是说中间的cognation层啊,大语言模型agent它调了一个任务之后,调了一个工具之后,它在等那个工具返回的结果,它再进一步的去往后走,而这个架构,它更像是平行执行的一个架构啊,我们的low level Controller和proceptor,一直在执行啊,直中间呢,我们再以一个更加低的频率呢,再去调接下来的这个,中层的一个任务的推理,或者是分解啊,在人形这边呢,其实我们会有一个更加明显的体现啊,其实大家可以基本上啊,看到现在目前为止,人形机器人他做的一些主要的工作,主要demo其实分为两部分,第一部分就是类似于啊,这个open AI figure one的这样一种结构,就是说它其实更关注的是一些啊,智能的任务,包括和人去直接进行沟通,能够对于任务进行拆解,但是它的action,大家可以看到都是接近于静态的action,什么意思,就是说我以最慢的速度执行,我也仍然能够执行下来啊,叫做静态的action,而另外一类任务呢,则更多的关注机器人的agility,就是它的灵活度,比如说以语数,或者Boston Dynamics为代表的这种机器人,这是真机视频啊,不是虚拟视频啊,这个它是做了一个后空翻的,这样一个纯电机的机器人,它首先是在模拟环境当中去使啊,使用深度强化学习,训练出了一个啊翻,翻空翻的这样一个policy,再通过SIM to real transfer,再到现实当中去啊,完成这个现实当中的,这个运动的一个控制啊,所以说在这两方面大家可以看到,其实呃,open AI的这样一个figure one机器人,就是中层的corporation架构,而这个语数,或both Dynamics的一些agility级别的控制,则是低低层的,这个非常高频的这样一个控制架构,而这两者智能,将会在非常快的速度之内,我们相信,它可以去完成一个范式的融合,好那么这就是我今天的分享,
我认为呢,决策大模型,是打造通用决策智能体的基础能力啊,它是我们新一代人工智能的底层技术,啊,然后他我们目前呢大致看到了两类的,范式的一个技术,包括,使用基于大语言模型做额外微调的,这样一种AIA技能的一个范式,以及啊通过end to end training啊,使用大的强化学习模块的这样一种啊,延展式的范式,这两者的融合呢,可能会在这个智能体的多层啊,通用决策智能体的多层上面,去完成一个相互的融合,能够为我们接下来的智能决策的,打开一个新的技术的一个通路,以上就是我的汇报啊,




![[MYSQL索引优化] 分页查询优化](https://img-blog.csdnimg.cn/direct/0673ba7212b0460aaa45f698cbbe4074.png)